To Understand Oracle Database basically we need to understand the Memory Architecture i.e. how the memory is used and for what purpose along with the basic processes (Oracle Process Architecture) that uses this memory for Interprocess Communication.
In this post we will understand the Oracle Memory Architecture in detail.
Oracle memory architecture is divided in following memory structure:-
- System Global Area (SGA):- This is a large, shared memory segment that virtually all Oracle processes will access at one point or another.
- Process Global Area (PGA): This is memory that is private to a single process or thread; it is not accessible from other processes/threads.
- User Global Area (UGA): This is memory associated with your session. It is located either in the SGA or the PGA, depending whether you are connected to the database using a shared server (it will be in the SGA), or a dedicated server (it will be in the PGA).
PGA (Program or Process Global Area)

PGA is the memory reserved for each user process connecting to an Oracle Database and is allocated when a process is created and deallocated when a process is terminated.
Contents of PGA:-
- Private SQL Area: Contains data such as bind information and run-time memory structures. It contains Persistent Area which contains bind information and is freed only when the cursor is closed and Run time Area which is created as the first step of an execute request. This area is freed only when the statement has been executed. The number of Private SQL areas that can be allocated to a user process depends on the OPEN_CURSORS initialization parameter.
- Session Memory: Consists of memory allocated to hold a session’s variable and other info related to the session.
- SQL Work Areas: Used for memory intensive operations such as: Sort, Hash-join, Bitmap merge, Bitmap Create.
Automatic PGA Memory Management
Before Auto-Memory management DBA had to allocate memory to:-
- SORT_AREA_SIZE: The total amount of RAM that will be used to sort information before swapping out to disk.
- SORT_AREA_RETAINED_SIZE: The amount of memory that will be used to hold sorted data after the sort is complete.
- HASH_AREA_SIZE: The amount of memory your server process can use to store hash tables in memory. These structures are used during a hash join, typically when joining a large set with another set. The smaller of the two sets would be hashed into memory and anything that didn’t fit in the hash area region of memory would be stored in the temporary tablespace by the join key.
To enable PGA Auto-Mem Management enable the parameter WORKAREA_SIZE_POLICY and allocate total memory to be used for this purpose to PGA_AGGREGATE_TARGET.
NOTE:- From 11gR1 You can set MEMORY_TARGET and auto-mem management for both SGA and PGA is taken care.
I came across several DBAs enquiring about how the PGA Memory is allocated and from their I cam to know about several misconceptions people are having so writing a short note on the same.
The PGA_AGGREGATE_TARGET is a goal of an upper limit. It is not a value that is preallocated when the database is started up. You can observe this by setting the PGA_AGGREGATE_TARGET to a value much higher than the amount of physical memory you have available on your server. You will not see any large allocation of memory as a result. A serial (nonparallel query) session will use a small percentage of the PGA_AGGREGATE_TARGET, typically about 5 percent or less. Hence its not that all of the memory allocated to PGA is granted at the time DB is started and gradually increases with number of user processes. The algorithm that I am aware of, allocates 5% of PGA to the user process until there is crunch on the PGA and then modifies the allocation based on the usage requirement of the user process.
SGA (System or Shared Global Area)
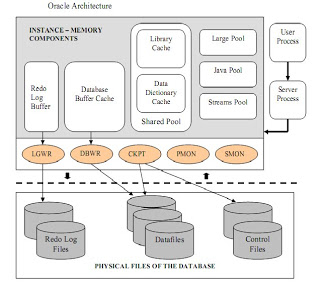
SGA is used to store database information that is shared by database processes. It contains data and control information for the Oracle Server and is allocated in the virtual memory if the computer where Oracle resides.
SGA consists of several memory structures:-
- Redo Buffer: The redo buffer is where data that needs to be written to the online redo logs will be cached temporarily, before it is written to disk. Since a memory-to-memory transfer is much faster than a memory-to-disk transfer, use of the redo log buffer can speed up database operation. The data will not reside in the redo buffer for very long. In fact, LGWR initiates a flush of this area in one of the following scenarios:
• Every three seconds
• Whenever someone commits
• When LGWR is asked to switch log files
• When the redo buffer gets one-third full or contains 1MB of cached redo log data - Buffer Cache: The block buffer cache is where Oracle stores database blocks before writing them to disk and after reading them in from disk. There are three places to store cached blocks from individual segments in the SGA:
• Default pool (hot cache): The location where all segment blocks are normally cached.
• Keep pool (warm cache): An alternate buffer pool where by convention you assign segments that are accessed fairly frequently, but still get aged out of the default buffer pool due to other segments needing space.
• Recycle pool (do not care to cache): An alternate buffer pool where by convention you assign large segments that you access very randomly, and which would therefore cause excessive buffer flushing of many blocks from many segments. There’s no benefit to caching such segments because by the time you wanted the block again, it would have been aged out of the cache. You would separate these segments out from the segments in the default and keep pools so they would not cause those blocks to age out of the cache. - Shared Pool: The shared pool is where Oracle caches many bits of “program” data. When we parse a query, the parsed representation is cached there. Before we go through the job of parsing an entire query, Oracle searches the shared pool to see if the work has already been done. PL/SQL code that you run is cached in the shared pool, so the next time you run it, Oracle doesn’t have to read it in from disk again. PL/SQL code is not only cached here, it is shared here as well. If you have 1,000 sessions all executing the same code, only one copy of the code is loaded and shared among all sessions. Oracle stores the system parameters in the shared pool. The data dictionary cache (cached information about database objects) is stored here. Shared Pool manages memory on an LRU basis, similar to buffer cache, which is perfect for caching and reusing data.
- Large Pool: The large pool is not so named because it is a “large” structure (although it may very well be large in size). It is so named because it is used for allocations of large pieces of memory that are bigger than the shared pool is designed to handle. Large memory allocations tend to get a chunk of memory, use it, and then be done with it. There was no need to cache this memory as in buffer cache and Shared Pool, hence a new pool was allocated. So basically Shared pool is more like Keep Pool whereas Large Pool is similar to the Recycle Pool. Large pool is used specifically by:
• Shared server connections, to allocate the UGA region in the SGA.
• Parallel execution of statements, to allow for the allocation of interprocess message buffers, which are used to coordinate the parallel query servers.
• Backup for RMAN disk I/O buffers in some cases. - Java Pool: The Java pool is used in different ways, depending on the mode in which the Oracle server is running. In dedicated server mode the total memory required for the Java pool is quite modest and can be determined based on the number of Java classes you’ll be using. In shared server connection the java pool includes shared part of each java class and Some of the UGA used for per-session state of each session, which is allocated from the JAVA_POOL within the SGA.
- Streams Pool: The Streams pool (or up to 10 percent of the shared pool if no Streams pool is configured) is used to buffer queue messages used by the Streams process as it moves or copies data from one database to another.
Automatic SGA Memory Management
By setting SGA_TARGET to a non-zero value (to a value you decide to allocate to SGA), the Automatic SGA Memory Management is enabled. For this the parameter statistics_level must be set to TYPICAL or ALL. If statistics collection is not enabled, the database will not have the historical information needed to make the necessary sizing decisions.
SGA_TARGET can be dynamically sized while the database is up and running, up to the setting of the SGA_MAX_SIZE parameter. This defaults to be equal to the SGA_TARGET, so if you plan on increasing the SGA_TARGET, you must have set the SGA_MAX_SIZE larger before starting the database instance.
NOTE:- From 11gR1 You can set MEMORY_TARGET and auto-mem management for both SGA and PGA is taken care.


Nice
LikeLiked by 1 person
It would be great of you could also explain AMM (MEMORY_TARGET & MEMORY_MAX TARGET) as you just explained SGA
LikeLike
Wow this is amazin
LikeLike
Hi, You’ve done an excellent job. I’ll certainly digg it and
recommend to my twitter followers personally. I’m confident they will be benefited
out of this website.
LikeLike
THIS WAS HELPFUL TO ME
LikeLike
Full depth knowledge regarding SGA and PGA, thank you
LikeLike
Hi ,
Can you please help me understand , how oracle internally represents tables in memory , like is it through some data structures or through pointer management ?
LikeLike
Hi ,
Can you please explain how tables are internally represented in memory , is it using pointers or some data structures being used?
LikeLike